
Image Colorization using Conditional GANs (Pix2Pix)
TL;DR
Pix2Pix Conditional GAN (U-Net generator + PatchGAN discriminator) trained on COCO 2017 (8,000 images). Converts greyscale to RGB at 128×128 resolution. Combined L1 + adversarial loss for pixel accuracy and visual quality. SSIM = 0.81, PSNR = 27.4 dB after 50 epochs. Gradient clipping + StepLR for stable GAN training.
Project Overview
This project applies a Conditional Generative Adversarial Network (cGAN) — specifically the Pix2Pix architecture — to the image-to-image translation task of colourising greyscale photographs. The model learns a mapping from greyscale input to realistic RGB output by training a U-Net-inspired generator adversarially against a PatchGAN discriminator.
Trained on 8,000 images from COCO 2017 (resized to 128×128), the model achieved SSIM = 0.81 and PSNR = 27.4 dB on a held-out test set of 1,000 images after 50 epochs (~6 hours on a single GPU). The combined L1 + adversarial loss was critical — L1 alone produced blurry, desaturated outputs; adversarial loss alone was unstable. Their combination produced sharp, vibrant colourisation.
Key Insights
- Loss function combination is the core engineering decision in Pix2Pix: L1 enforces pixel-level accuracy but drives outputs toward the mean (blurry, grey-biased); adversarial loss drives visual realism but destabilises training. λ=100 weighting on L1 proved optimal.
- PatchGAN discriminator classifies 70×70 overlapping patches rather than the full image — this is what enables the discriminator to enforce local texture realism rather than just global plausibility.
- GAN training instability was the primary challenge — mode collapse occurred without gradient clipping. Clipping at norm=1.0 stabilised training from epoch 15 onward.
- Colourisation is inherently ambiguous — a greyscale sky could be blue or grey; a greyscale car could be any colour. SSIM and PSNR measure pixel-level similarity to ground truth, but perceptual quality can exceed these scores when the model chooses a plausible-but-different colour.
Technical Implementation
- Dataset:
- COCO 2017 — 8,000 training images, 1,000 test images. Images resized to 128×128. Greyscale conversion applied as input; original RGB as target.
- Data augmentation: random horizontal flip, random crop from 143×143 → 128×128 (standard Pix2Pix augmentation).
- Generator (U-Net):
- 8-layer encoder-decoder with skip connections. Encoder uses Conv → BatchNorm → LeakyReLU; decoder uses ConvTranspose → BatchNorm → ReLU.
- Skip connections from encoder to decoder preserve spatial detail at multiple scales — essential for colour localisation.
- Discriminator (PatchGAN):
- 5-layer convolutional network classifying 70×70 image patches as real or fake.
- Conditional — receives concatenated [greyscale input, colour output] so it evaluates whether the colourisation is consistent with the input content.
- Training:
- Adam optimiser (lr=0.0002, β1=0.5 — standard GAN setting). 50 epochs, batch size 16.
- Gradient clipping at norm=1.0 applied to generator to prevent training collapse.
- StepLR scheduler: lr × 0.5 every 10 epochs after epoch 20.
- Training time: ~6 hours on a single NVIDIA GPU.
- Evaluation:
- SSIM = 0.81 — structural similarity to ground truth (1.0 = perfect).
- PSNR = 27.4 dB — signal-to-noise ratio; values above 25 dB are generally considered good quality for image reconstruction.
Image Preview
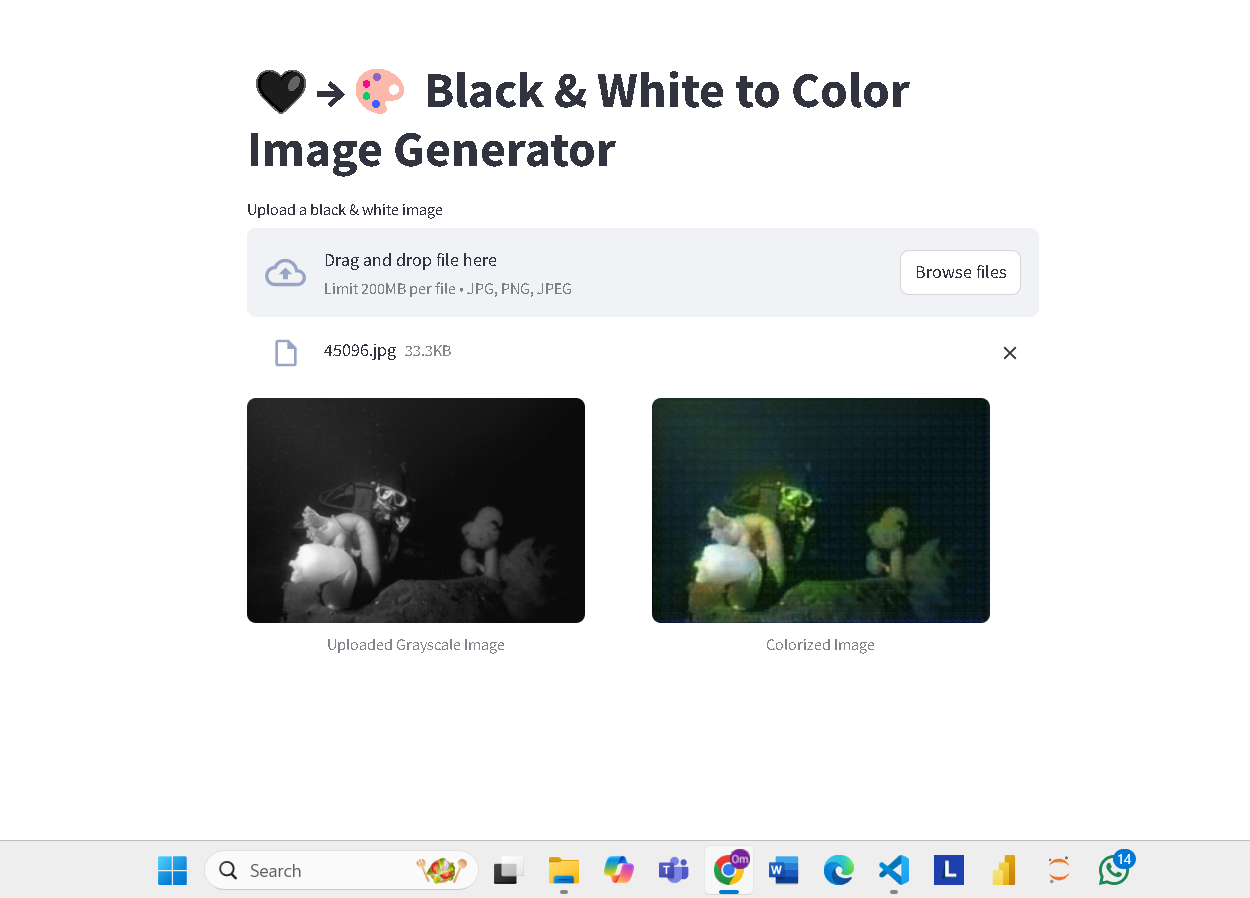
Key Learnings
- What surprised me most: GAN training failure modes are silent — the generator can appear to be learning (loss decreasing) while actually entering mode collapse. Monitoring generated image diversity visually every 5 epochs was more informative than loss curves alone.
- What I'd do differently first: Start with a smaller dataset and confirm the architecture works before scaling. Early experiments on 500 images revealed the gradient clipping requirement, saving significant GPU time.
- The skip connection insight: Removing skip connections from the U-Net caused the model to lose spatial correspondence between input and output — generated images had correct colours but wrong colour placement. Skip connections are not optional in Pix2Pix.
- Perceptual metrics vs pixel metrics: SSIM and PSNR penalise the model equally for choosing blue vs grey sky even if both are perceptually valid. This is a fundamental limitation of pixel-based evaluation for generative tasks — FID (Fréchet Inception Distance) would be a better complementary metric.
Future Work
- Train on a larger, more diverse dataset (full COCO 2017 — 118k images) to improve generalisation to unusual subjects and colour schemes.
- Add FID evaluation alongside SSIM/PSNR — FID better captures perceptual quality for generative models.
- Experiment with higher resolution (256×256) using a deeper U-Net — 128×128 produces visible pixelation on large flat areas.
Built by Om Patel — ML Engineer & Data Scientist.
Explore more projects on my
Portfolio.